【头歌】大数据分析及应用:Python正则表达式 - 替换&Python正则表达式 - 入门&Python 正则表达式re模块
如需查看过关测评代码直接点击【测评代码】快速查看
-
实验描述
-
Python正则表达式 - 替换
-
第1关:正则表达式替换
-
任务描述
本关任务:根据具体要求完成字符串的替换。
-
相关知识
简单的入门案例能帮助你在真实开发环境下,使用正则表达式时更加得心应手。好了,接下来让我们一起来看看正则表达式的替换。
正则表达式替换
-
示例
1:使用
re.sub()函数将str中的, all rights reserved替换为空格(str中的空格不替换)。import re str ='2010-2019 , all rights reserved 信息科技有限公司' after_Replacement1 =re.sub("[,a-z\s]+"," ",str) print(after_Replacement1)输出:
2010-2019 信息科技有限公司 -
示例
2:使用
re.sub+lambda将str字符串中的2016-2019字符串替换为2016年-2019年成立。import re str ='2016-2019 信息科技有限公司' after_Replacement2 = re.sub('(\\d+)\\W(\\d+).*(\W+)', lambda x:x.group(1)+'年-'+x.group(2)+'年成立'+x.group(3),str) print(after_Replacement2)输出:
2016年-2019年成立 信息科技有限公司
-
-
编程要求
请在右侧编辑器
Begin - End区域内进行代码补充,将str字符串中mn、123、a、b、c、d、e、f、7全部替换为空。 -
测试说明
平台会对你编写的代码进行测试:
测试输入:
mn123abcdef789abcdefghijklmn78945213预期输出:
89ghijkl8945213
-
-
-
Python正则表达式 - 入门
-
第1关:查找第一个匹配的字符串
-
任务描述
本关任务:学会导入
python的正则表达式库,使用该库方法的search方法编写一个匹配小程序。该方法能查看某个学生名字是否在此学生信息中。 -
相关知识
- 为了完成本关任务,你需要掌握:
- 如何在 python 中引入正则表达式库;
re库中search方法的使用。
-
在Python 中使用正则表达式
正可谓人生苦短,我用
Python。Python有个特点就是库非常多,自然拥有正则匹配这种常见的库,并且此库已经嵌入在Python标准库中,使用起来非常方便,只需要在代码中导入re模块即可。import rePython的re模块,使得Python具备了使用全部正则表达式的功能。为了让我们灵活的使用正则表达式,现在咱们的任务就是学习正则在re库中的使用。 -
最基础正则表达式
正则表达式是一个以简单直观的方式通过寻找模式匹配文本的工具。
听起来比较复杂,实际非常简单,下面开始体验最简单的正则表达式。最简单的正则表达式是些仅包含简单字母数字字符的表达式——不包含任何其他字符,在这种情况下正则表达式完完全全就是一个正常的字符串。
举例说明,我们要匹配
张明,那么张明这两个字符就是我们需要的正则表达式。 -
正则匹配函数
知道了最基础正则表达式,可是如何在
python中使用了?首先我们学习第一个函数,search()函数,它的目的是接收一个正则表达式和一个字符串,并返回发现的第一个匹配的字符串。import re a = re.search(r'fox','the quick brown fox jumpred') #第一个参数为正则表达式,第二个参数为要处理的字符串 print(a.span()) # span方法获取的是正则表达式匹配到的位置 b = re.search(r'www','the quick brown fox jumpred') print(b) #如果匹配不到则会返回None输出如下:
(16, 19) None如何匹配到了,我们输出他在正则表达式中的位置,如果没有匹配到,则输出为空。
- 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 导入相关包;
- 查看此信息是不是
张明的信息,查找结果存储在is_zhangming变量中。
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
张伟 86-14870293148;预期输出:
None测试输入:
张明;预期输出:
(0,2)
-
-
第2关:基础正则表达式--字符组
-
任务描述
本关任务:运用正则表达式的字符组表示方法,编写一个能从文本中快速匹配到
python和Python的小程序。 -
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式的字符组的表达方式;
Python中re模块中获取多个匹配的使用方法。
在上一个任务中,已经了解了只包含简单字母数字的正则表达式,但如果仅仅如此,那么太小瞧正则表达式的威力了。正则表达式强大的地方在于能够指定用于匹配的文本模式。本关来学习正则表达式的字符组匹配。
-
获得多个匹配信息
在很多常见的场景中需要进行多个匹配,比如在学生名单中过滤出所有的张姓学生的个数。
如果有这种需求咱们可以使用
re模块中的findall或者finditer方法。两个方法的区别在于findall返回的是一个列表,finditer返回的是一个生成器。l = re.findall(r'张','张三 张三丰 张无忌 张小凡') print(l) ['张', '张', '张', '张']在这个例子中,我们会发现
findall返回了4个“张”,这是因为“张”字在后面的字符串中出现了4次。即findall返回了所有的匹配信息。 -
字符组
字符组允许匹配一组可能出现的字符,在正则表达式中用
[]表示字符组标志,举个例子。'I like Python3 and I like python2.7 '在这句话中,既有大写的
Python,又有全部是小写的python。如果我要求都匹配出来,这时候该怎么操作了?这就是正则匹配中字符组的威力了。下面看下示例。a = re.findall(r'[Pp]ython','I like Python3 and I like python2.7 ') print(a)['Python', 'python']可以发现
[Pp]既可以匹配大写的P也可以匹配小写的p,这里值的我们注意的是[Pp]仅匹配一个字符,他表示匹配在这个[]内的某一个。
- 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 从文本中快速匹配到
python和Python的小程序,输出匹配到的所有内容。
- 从文本中快速匹配到
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
I LIKE Python3 and i like python2.7;预期输出:
[Python, python]
-
-
第3关:基础正则表达式--区间与区间取反
-
任务描述
本关任务:运用正则表达式的区间表示方法,编写一个能从文本中快速匹配到数字与不是数字字符的小程序。
-
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式区间的表达方式;
- 正则表达式区间取反的表达方式。
本关来学习正则表达式区间与区间取反的相关知识。
-
区间
有一些常见的字符组非常大,比如,我们要匹配的是任意数字,如果依照上述代码,每次我们都需要使用
[0123456789]这种方式明显很不明智,而如果要匹配从a-z的字母,我们也这样编写代码的话,肯定会让我们崩溃。为了适应这一点,正则表达式引擎在字符组中使用连字符(-)代表区间,所以我们匹配任意数字可以使用
[0-9],所以如果我们想要匹配所有小写字母,可以写成[a-z],想要匹配所有大写字母可以写成[A-Z]。可能我们还有个需求:匹配连字符。因为
-会被正则表达式引擎理解为代表连接区间,所以这个时候我们需要对-进行转义。示例:
a = re.findall(r'[0-9]','xxx007abc') b = re.findall(r'[a-z]','abc001ABC') c = re.findall(r'[A-Za-z0-9]','abc007ABC') d = re.findall(r'[0-9\-]','0edu 007-edu') print(a) print(b) print(c) print(d)执行结果如下:
['0', '0', '7'] ['a', 'b', 'c'] ['a', 'b', 'c', '0', '0', '7', 'A', 'B', 'C'] ['0', '0', '0', '7', '-'] -
区间取反
到目前为止,我们定义的字符组都是由可能出现的字符定义,不过有时候我们可能希望根据不会出现的字符定义字符组,例如:匹配不包含数字的字符组。
a = re.findall(r'[^0-9]','xxx007abc') b = re.search(r'[^0-9]','xxx007abc') print(a) print(b)执行结果如下:
['x', 'x', 'x', 'a', 'b', 'c'] <re.Match object; span=(0, 1), match='x'>可以通过在字符数组开头使用
^字符实现取反操作,从而可以反转一个字符组(意味着会匹配任何指定字符之外的所有字符)。接下来再看一个表达式:
n[^e]这意味着字符n接下来的字符是除了e之外所有的字符。a = re.findall(r'n[^e]','final') b = re.search(r'n[^e]','final') c = re.findall('r[n[^e]]','Python') print(a) print(b) print(c)执行结果如下:
['na'] <re.Match object; span=(2, 4), match='na'> []这里我们可以发现
a和b匹配的是na,字符a因为不是e所以可以被匹配,而变量c的值为空,在这里正则表达式引擎只匹配到了字符串n的位置,而n之后没有任何可以匹配[^e]的字符了,所以这里也匹配失败。[] <re.Match object; span=(0, 6), match='master'>
- 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 匹配数字字符信息;
- 匹配不是数字字符的信息。
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
Python3 and python2.7;预期输出:
['3', '2', '7'] ['P', 'y', 't', 'h', 'o', 'n', ' ', 'a', 'n', 'd', ' ', 'p', 'y', 't', 'h', 'o', 'n', '.']
-
-
第4关:基础正则表达式--快捷方式
-
任务描述
本关任务:运用正则表达式的快捷方式的表示方法,编写一个能从文本中快速匹配到任意单词和不是单词的
Python小程序。 -
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式快捷方式的表达方式;
- 正则表达式快捷方式取反的表达方式;
本关来学习正则表达式的快捷方式与快捷方式取反。
-
快捷方式
在正则表达式的使用过程中,人们为了快捷表达与方便阅读,提取了几种普通字符组,并在正则表达式引擎中预定义了其快捷方式。如果我们想要定义单词,以目前学到的可能会使用
[A-Za-z],但是,很多单词都是使用该字母以外的字符。比如中文,以及其他语言。正则表达式引擎提供了一些快捷方式:
\w,与 “任意单词字符”匹配,在Python3中,基本上可以匹配任何语言的任意单词。- 而当我们想要匹配任意数字的时候,也可以使用快捷方式
\d,d即digit。在Python3中,它除了可以和[0-9]匹配,还可以和其他语言的数字匹配。 \s快捷方式匹配空白字符,比如空格,tab、换行等。\b快捷方式匹配一个长度为0的字符串,但是,他仅仅在一个单词开始或结尾处匹配,这被称为词边界快捷方式。
快捷方式 描述 \w 与任意单词匹配 \d 与任意数字匹配 \s 匹配空白字符,比如空格,换行等 \b 匹配一个长度为0的子串 示例1
a = re.findall(r'\w','学好Python 大展拳脚') b = re.search(r'\w','python3') c = re.search(r'\d','编号89757') print(a) print(b) print(c)执行结果输出如下:
['学', '好', 'P', 'y', 't', 'h', 'o', 'n', '大', '展', '拳', '脚']<re.Match object; span=(0, 1), match='p'><re.Match object; span=(2, 3), match='8'>
这里
findall会返回所有能匹配的值,search只会返回第一个匹配到的值。示例2
a = re.findall(r'\bmaster\b','masterxiao-master-xxx master abc') #单词字符后面或前面不与另一个单词字符直接相邻 b = re.search(r'\bmaster\b','master') print(a) print(b)执行结果输出如下:
['master', 'master'] None示例3
a = re.search(r'\smaster\s','masterxiao master xxx') print(a)执行结果输出如下:
<re.Match object; span=(10, 18), match=' master '> -
快捷方式取反
之前提到了取反,快捷方式也可以取反, 例如对于
\w的取反为\W,可以发现将小写改写成大写即可。注意:这里
\B有所不同,\b匹配的是在单词开始或结束位置长度为0的子字符串,而\B匹配不在单词开始和结束位置的长度为0的子字符串。a = re.findall(r'\Bmaster\B','masterxiao master xxx master abc') #单词字符后面或前面不与另一个单词字符直接相邻 b = re.search(r'master\B','masterxiao') print(a) print(b)执行结果输出如下:
[] <re.Match object; span=(0, 6), match='master'>
- 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 匹配单词字符,并输出;
- 匹配不是单词的字符,并输出。
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
Python3 and python2.7;预期输出:
['P', 'y', 't', 'h', 'o', 'n', '3', 'a', 'n', 'd', 'p', 'y', 't', 'h', 'o', 'n', '2', '7'] [' ', ' ', '.']
-
-
第5关:字符串的开始与结束
-
任务描述
本关任务:使用正则表达式的方法编写一个小程序。该程序可以:
- 匹配到该字符串是否以
educoder开头,并输出该字符串的位置; - 匹配到该字符串是否以
educoder结尾,并输出该字符串的位置。
- 匹配到该字符串是否以
-
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式字符串开始的使用方法;
- 正则表达式字符串结束的使用方法。
字符串的开始和结束
在日常生活中,一个事情的开始与结束都是一件比较重要的事情,在字符串匹配的过程中也是如此,字符串的开始与结束式一个重要的特征。比如我们要获取判断字符串是否以
python开头,是否以python结尾。对于这种情况,之前匹配方法就有点不够用了,因此在正则表达式中 用
^可以表示开始,用$表示结束,示例如下:a = re.search(r'^python', 'python is easy') b = re.search(r'python$', 'python is easy') c = re.search(r'^python', 'i love python') d = re.search(r'python$', 'i love python') print(a.span()) print(b) print(c) print(d.span())执行输出结果如下:
(0, 6) None None (7, 13)可以发现,在上述例子中,
python is easy和i love python都存在python字符串,但是一个在开头一个在结尾,因此变量a和变量d都匹配到了信息。其他则无法匹配到信息。 - 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 匹配以
educoder开头的字符串,并存储到变量 a; - 匹配以
educoder结束的字符串,并存储到变量 b。
- 匹配以
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
educoder can help you;预期输出:
(0, 8) None测试输入:
i love educoder;预期输出:
None (7, 15)测试输入:
you can make educoder better预期输出:
None None
-
-
第6关:任意字符
-
任务描述
本关任务:使用正则表达式的方法编写一个小程序。该程序可以判断该字符串是否包含
(任意字符)ython的子字符串,并输出匹配到的结果。 -
相关知识
为了完成本关任务,你需要掌握:
- 正则表达式通配符的使用;
python正则表达式编程。
通配符
在生活中我们经常会有这么一种场景,我们记得某个人名为孙x者,就是不记得他叫孙行者,在正则表达式中针对此类场景,产生了通配符的概念,用符号
.表示。它代表匹配任何单个字符,不过值得注意的是,它只能出现在方括号字符组以外。值得注意的是:
.字符只有一个不能匹配的字符,也就是换行(\n),不过让.字符与换行符匹配也是可能的,以后会讨论。示例如下:a = re.findall(r'p.th.n','hello python re') b = re.findall(r'p.....','学好 python 人见人爱') print(a) print(b)输出:
['python'] ['python'] -
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 匹配出测试集中的包含
(任意字符)ython的子字符串,并输出数组子字符串。
- 匹配出测试集中的包含
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
2ython;预期输出:
['2ython']。测试输入:
ython;预期输出:
[]。
-
-
第7关:可选字符
-
任务描述
本关任务:使用正则表达式的方法编写一个小程序。该程序可以判断该字符串是否包含
he或者she的子字符串,并输出匹配到的结果。 -
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式可选字符的使用方法;
python正则表达式编程。
可选字符
到目前为止,我们看到的正则表达式都是在正则表达式中的字符与被搜索的字符串中的字符保持
1:1的关系。不过有时,我们可能想要匹配一个单词的不同写法,比如
color和colour,或者honor与honour。这个时候我们可以使用
?符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现零次或一次。a = re.search(r'honou?r','He Served with honor and distinction') b = re.search(r'honou?r','He Served with honour and distinction') c = re.search(r'honou?r','He Served with honou and distinction') print(a) print(b) print(c)执行结果输出如下:
<re.Match object; span=(15, 20), match='honor'> <re.Match object; span=(15, 21), match='honour'> None可以发现,在上述三个例子中,正则表达式为
honou?r,这里可以匹配的是honor和honour不能匹配honou,可以知道的是?确定了前一个u是可选的。在第一个示例中,没有u,是没有问题可以匹配的;在第二个示例中,u存在这也没有问题;在第三个例子中,u存在但是r不存在,这样就不能匹配了。 - 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,具体任务如下:- 匹配出字符串中的
she或者he,并输出匹配到的信息。
- 匹配出字符串中的
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
she is;预期输出:
she。测试输入:
he;;预期输出:
he。
-
-
第8关:重复区间
-
任务描述
本关任务:编写一个正则表达式的小程序,该小程序具有以下功能:
- 匹配到字符串中重复出现
2的数字内容,并打印出其匹配到的列表; - 匹配到字符串中重复出现
4次到7次的数字内容,并打印出其匹配到的列表。
- 匹配到字符串中重复出现
-
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式重复区间的表达方法;
Python正则编程。
重复
到目前为止,我们只是学习了关于仅出现一次的字符串匹配,在实际开发过程中,这样肯定不能满足需求,比如要匹配电话号码,比如匹配身份证号,这些都是很多个数字组成的。
如果遇到这样的情况,我们可能期望一个字符组连续匹配好几次。
在正则表达式在一个字符组后加上
{N}就可以表示{N}之前的字符组出现N次。举个例子:a = re.findall(r'[\d]{4}-[\d]{7}','张三:0731-8825951,李四:0733-8794561') print(a)输出为:
['0731-8825951', '0733-8794561']重复区间
可能有时候,我们不知道具体匹配字符组要重复的次数,比如身份证有
15位也有18位的。这里重复区间就可以出场了,语法:
{M,N},M是下界而N是上界。举个例子:
a = re.search(r'[\d]{3,4}','0731') b = re.search(r'[\d]{3,4}','073') print(a) print(b)执行结果输出如下:
<re.Match object; span=(0, 4), match='0731'> <re.Match object; span=(0, 3), match='073'>通过上述代码,我们发现
[\d]{3,4}既可以匹配3个数字也可以匹配4个数字,不过当有4个数字的时候,优先匹配的是4个数字,这是因为正则表达式默认是贪婪模式,即尽可能的匹配更多字符,而要使用非贪婪模式,我们要在表达式后面加上?号。a = re.search(r'[\d]{3,4}?','0731') b = re.search(r'[\d]{3,4}?','073') print(a) print(b)执行结果输出如下:
<re.Match object; span=(0, 3), match='073'> <re.Match object; span=(0, 3), match='073'>值得注意的是,上述代码这样子使用就只能匹配
3个数字而无法匹配4个了。 - 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,匹配并输出符合如下要求的字符串:- 字符串中重复
2个数字的子字符串; - 重复
4-7个数字组成的子字符串。
- 字符串中重复
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
张3:0731-8825951,李4:0733-8794561;预期输出:
['0731', '8825951', '0733', '8794561']。
-
-
第9关:开闭区间与速写
-
任务描述
本关任务:使用正则表达式重复速写的功能编写一个小程序,该小程序能根据需求能重复匹配字符串中多个字符,并输出内容。
-
相关知识
- 为了完成本关任务,你需要掌握:
- 正则表达式重复基本知识;
- 正则表达式开闭区间的基本知识;
- 正则表达式重复速写的方法。
开闭区间
在实际生活中,我们经常会遇到一种场景,我们知道此处会填写什么格式,但是我们不确定填写的内容。比如说每月支出,我们知道此处一定是数字,但是不确定这个月支出了多少钱,是
3位数,还是4位数,说不定这个月就花了10个亿。这时候我们可以用开区间来表示此范围,如下所示:a = re.search(r'[\d]{1,}','我这个月花了:5元') print(a)输出为:
<re.Match object; span=(7, 8), match='5'>速写
在正则表达式中,我们可以通过开闭区间来应对此种重复次数没有边界的场景。但是如此常见的需求,为什么不简单一点用一个符号表示出来了,每次都这样写不累么?是的,不仅累而且影响阅读,因此在正则表达式中,推出了
2个符号:符号 含义 '+' 重复匹配1个或多个 '*' 重复匹配0个或多个 重复符号
+符号
+用来表示重复一次到无数次,如下示范:a = re.findall(r'[\d]+','0731-8859456') print(a)执行结果输出如下:
['0731', '8859456']重复符号
*符号
'*'用来表示重复0次到无数次,如下示范:a = re.findall(r'[\d]*','0731-8859456') print(a)执行结果输出如下:
['0731', '', '8859456', '']为什么这一次的输出多了两个
''?因为在匹配
-与末尾的字符时,没有匹配到一个数字,但是我们匹配到了0个数字,因此输出了空的字符串''。 - 为了完成本关任务,你需要掌握:
-
编程要求
请仔细阅读右侧代码,根据方法内的提示,在
Begin - End区域内进行代码补充,匹配并输出符合如下要求的字符串:- 重复数字
5次及以上的子字符串; - 重复数字
1次及以上的子字符串。
- 重复数字
-
测试说明
补充完代码后,点击测评,平台会对你编写的代码进行测试,当你的结果与预期输出一致时,即为通过。
测试输入:
0731-8859456;预期输出:
['8859456'] ['0731', '8859456']
-
-
-
Python 正则表达式re模块
-
第1关:正则表达式基础知识
-
任务描述
本关任务:编写代码,通过
re.findall()模块匹配内容。 -
相关知识
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,来筛选出符合这个规则的内容。
可以简单理解为:一个强大的搜索工具中,正则表达式就是你要搜索内容的条件表达式。
为了完成本关任务,你需要掌握:1.正则模块函数
re.findall(),2.各种正则表达式元字符的含义。以下实例均可在
命令行窗口中练习。re.findall()函数
作用:遍历整个字符串,可以获取其中所有匹配的字符串,返回一个列表。
一般用法:
re.findall(r'正则表达式','要匹配的文本')
从小练习接触正则
-
从字符串中匹配单词
to:import re text = "0537-146987425,0537-299656897,The moment you think about giving up,think of the reason why you held on so long. Total umbrella for someone else if he, you’re just not for him in the rain.Never put your happiness in someone else’s hands.Sometimes you have to give up on someone in order to respect yourself. aaaa bbbbcc d dddddd" print(re.findall(r'to',text))运行结果如下:

-
匹配在
text中以g开头的所有单词:print(re.findall(r'\bg\w*?\b',text))
-
查找出
xxxx-xxxxxxxxx格式的数据:print(re.findall(r'\d{4}-\d{8}',text))
正则表达式元字符
通过上面几个小练习,你对正则表达式有了一定的认识,但还是感觉云里雾里不熟悉吧。这是因为正则表达式中的“公式”代表的含义你都不了解。想要学好正则表达式,你就要熟悉这些
元字符代表的含义,除了多练习和多记忆没有什么好办法了。(以下为一部分常用元字符的介绍,剩余部分用到的时候再去熟悉;)
元字符 功能说明 ^ 匹配字符串的开始 $ 匹配字符串的结束 . 匹配除换行符以外的任意字符 \d 匹配数字 \b 匹配单词头或单词尾 \w 匹配任何字母、数字以及下划线 \s 匹配任何空白字符,包括空格、制表符、换页符 \B 与\b相反,匹配非单词边界 \W 与\w相反 \S 与\s相反 {m,n} {}前的字符或子模式重复至少m次,至多n次 -
-
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
- 匹配字符单词
Love; - 匹配以
w开头的完整单词; - 查找字母长度为
3的单词。
- 匹配字符单词
-
测试说明
平台会对你编写的代码进行测试:
测试输入:
Love your parents. We are too busy growing up yet we forget that they are already growing.预期输出:
['Love'] ['we'] ['are', 'too', 'yet', 'are']
-
-
第2关:re 模块中常用的功能函数(一)
-
任务描述
上一关我们已经接触了
re.findall()函数,现在我们继续学习 Python 正则模块中常用的功能函数吧。本关任务:编写代码,匹配相应的内容。
-
相关知识
为了完成本关任务,你需要掌握:1.
compile()函数,2.match()函数,3.search()函数。以下实例均可在
命令行窗口中练习。-
compile()函数
编译正则表达式模式,返回一个对象的模式(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率)。
格式:
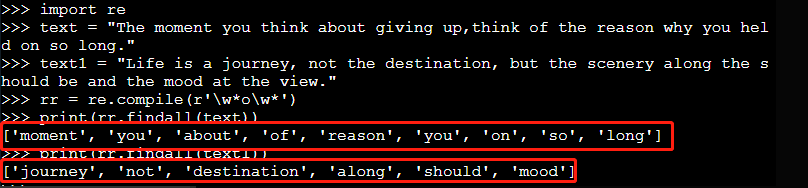
re.compile(pattern,flags=0)import re text = "The moment you think about giving up,think of the reason why you held on so long." text1 = "Life is a journey,not the destination,but the scenery along the should be and the mood at the view." rr = re.compile(r'\w*o\w*') print(rr.findall(text)) #查找text中所有包含'o'的单词 print(rr.findall(text1)) #查找text1中所有包含'o'的单词运行结果如下:
-
pattern: 编译时用的表达式字符串(即正则表达式); -
flags:(可选)编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:标志 含义 re.S(DOTALL) 使.匹配包括换行在内的所有字符 re.I(IGNORECASE) 使匹配对大小写不敏感 re.L(LOCALE) 做本地化识别(locale-aware)匹配,法语等 re.M(MULTILINE) 多行匹配,影响^和$ re.X(VERBOSE) 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 re.U 根据Unicode字符集解析字符,这个标志影响\w,\W,\b,\B
-
-
match()函数
在字符串刚开始的位置匹配,在开头匹配到目的字符便返回,如果开头没有目的字符将匹配失败,返回
None。格式:
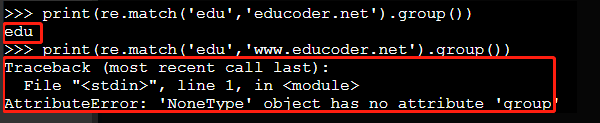
re.match(pattern, string, flags=0)print(re.match('edu','educoder.net').group()) print(re.match('edu','www.educoder.net').group())运行结果如下:
注:
match()函数返回的是一个match object对象,而match object对象有以下方法:group():返回被正则匹配的字符串;start():返回匹配开始的位置;end():返回匹配结束的位置;span():返回一个元组包含匹配 (开始,结束) 的位置;groups():返回正则整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。
-
search()函数
re.search()函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回。如果字符串没有匹配,则返回None。格式:
re.search(pattern, string, flags=0)print(re.search('edu','www.educoderedu.net').group()) print(re.search('eduaaa','www.educoderedu.net').group())运行结果如下:

注:
match()和search()比较类似,它们的区别在于match()只匹配字符串的开头,如果开头没有出现目的字符串,即使后面出现了也不会进行匹配;search()函数会在整个字符内匹配,只要找到一个目的字符串就返回。
-
-
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
- 用
compile方法,匹配测试输入字符串text中所有含字母i的单词; - 在字符串起始位置匹配字符
The是否存在,并返回被正则匹配的字符串; - 在整个字符串查看字符
is是否存在,并返回被正则匹配的字符串。
- 用
-
测试说明
平台会对你编写的代码进行测试:
测试输入:
There is a time in life that is full of uneasiness.We have no other choice but to face it.预期输出:
['is', 'time', 'in', 'life', 'is', 'uneasiness', 'choice', 'it'] The is
-
-
第3关:re 模块中常用的功能函数(二)
-
任务描述
本关任务:编写代码,匹配相应的内容。
-
相关知识
- 为了完成本关任务,你需要掌握:
finditer()函数;split()函数;sub()函数;subn()函数。
以下实例均可在
命令行窗口中练习。-
finditer()函数
搜索字符串,返回一个
Match对象的迭代器(包含匹配的开始和结束的位置,如下图中的i所示)。找到正则匹配的所有子串,把它们作为一个迭代器返回。格式:
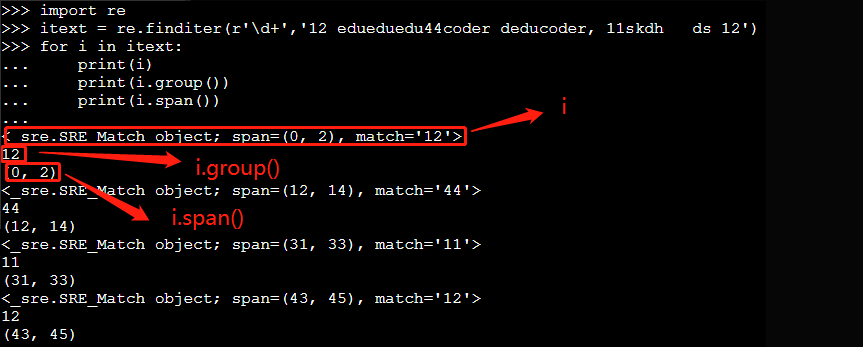
re.finditer(pattern, string, flags=0);itext = re.finditer(r'\d+','12 edueduedu44coder deducoder, 11skdh ds 12') #匹配所有的数字 for i in itext: print(i) print(i.group()) print(i.span()) #span()返回一个元组包含匹配 (开始,结束) 的位置运行结果如下:
-
split()函数
按照能够匹配的子串,将
string分割后返回列表。格式:
re.split(pattern, string);可以使用
re.split来分割字符串,如:re.split(r'\s+', text)将字符串,按空格分割成一个单词列表。以数字为分割符,将字符串分割:
print(re.split(r'\d+','asas2kdjs4jds5djdfj1djf0'))运行结果如下:

-
sub()函数
使用
re替换string中每一个匹配的子串后,返回替换后的字符串。格式:
re.sub(pattern, repl, string, count);用
-替代,如下:import re text = "aaa,bbb,ccc,ddd" print(re.sub(r',', '-', text))运行结果如下:

-
subn()函数
返回替换次数。
格式:
subn(pattern, repl, string, count=0, flags=0);解释:用
A替换123中的1,结果为A23,repl就是指的A。把所有的数字替换为
A:print(re.subn('\d','A','1asd2dkjf34'))运行结果如下:

subn()不仅返回了替换后的字符串,还返回了替换的次数。
- 为了完成本关任务,你需要掌握:
-
编程要求
根据提示,补全右侧编辑器中 Begin 至 End 区间的代码,实现以下功能:
- 匹配测试输入的字符串
text中以t开头的所有单词并显示; - 用空格分割句子;
- 用
-代替句子中的空格; - 用
-代替句子中的空格,并返回替换次数。
- 匹配测试输入的字符串
-
测试说明
平台会对你编写的代码进行测试:
平台测试输入:
The moment you think about giving up,think of the reason why you held on so long.预期输出:
think think the ['The', 'moment', 'you', 'think', 'about', 'giving', 'up,', 'think', 'of', 'the', 'reason', 'why', 'you', 'held', 'on', 'so', 'long.'] The-moment-you-think-about-giving-up,-think-of-the-reason-why-you-held-on-so-long. ('The-moment-you-think-about-giving-up,-think-of-the-reason-why-you-held-on-so-long.', 16)
-
-
-
-
测评代码
-
Python正则表达式 - 替换
-
Python正则表达式 - 入门
-
第1关:查找第一个匹配的字符串
# coding=utf-8 # 在此导入python正则库 ########## Begin ########## import re ########## End ########## check_name = input() # 在此使用正则匹配'张明'的信息,结果存储到is_zhangming中 ########## Begin ########## is_zhangming=re.search(r'张明',check_name) ########## End ########## if is_zhangming is not None: print(is_zhangming.span()) else: print(is_zhangming) -
第2关:基础正则表达式--字符组
# coding=utf-8 import re input_str = input() # 编写获取python和Python的正则,并存储到match_python变量中 ########## Begin ########## match_python = re.findall(r'[Pp]ython',input_str) ########## End ########## print(match_python) -
第3关:基础正则表达式--区间与区间取反
# coding=utf-8 import re input_str = input() # 1、编写获取到数字的正则,并输出匹配到的信息 ########## Begin ########## a = re.findall(r'[\d]',input_str) print(a) ########## End ########## # 2、编写获取到不是数字的正则,并输出匹配到的信息 ########## Begin ########## b = re.findall(r'[^\d]',input_str) print(b) ########## End ########## -
第4关:基础正则表达式--快捷方式
# coding=utf-8 import re input_str = input() # 1、编写获取到单词的正则,并输出匹配到的信息 ########## Begin ########## a = re.findall(r'[a-zA-Z\d]',input_str) print(a) ########## End ########## # 2、编写获取到不是单词的正则,并输出匹配到的信息 ########## Begin ########## b = re.findall(r'[^a-zA-Z\d]',input_str) print(b) ########## End ########## -
第5关:字符串的开始与结束
# coding=utf-8 import re input_str = input() # 1、编写获取到以educoder开头的正则,并存储到变量a ########## Begin ########## a = re.search(r'^educoder', input_str) ########## End ########## if a is not None: print(a.span()) else: print(a) # 2、编写获取到以educoder结束的正则,并存储到变量b ########## Begin ########## b = re.search(r'educoder$', input_str) ########## End ########## if b is not None: print(b.span()) else: print(b) -
第6关:任意字符
# coding=utf-8 import re input_str = input() # 编写获取(任意字符)+ython的字符串,并存储到变量a中 ########## Begin ########## a = re.findall(r'.ython',input_str) ########## End ########## print(a) -
第7关:可选字符
# coding=utf-8 import re input_str = input() # 编写获取she或者he的字符串,并存储到变量a中 ########## Begin ########## a = re.findall(r's?he',input_str) ########## End ########## print(a) -
第8关:重复区间
# coding=utf-8 import re input_str = input() # 1、基于贪心模式匹配字符串中重复出现2个数字的子字符串,并存储到变量a。 ########## Begin ########## a = re.findall(r'[\d]{2}',input_str) ########## End ########## print(a) # 2、基于贪心模式匹配字符串中重复出现4-7个数字的子字符串,并存储到变量b。 ########## Begin ########## b = re.findall(r'[\d]{4,7}',input_str) ########## End ########## print(b) -
第9关:开闭区间与速写
# coding=utf-8 import re input_str = input() # 1、基于贪心模式匹配字符串中连续出现5个数字以上的子字符串,并存储到变量a。 ########## Begin ########## a = re.findall(r'[\d]{5,}',input_str) ########## End ########## print(a) # 2、匹配字符串中都为数字的子字符串,并存储到变量b。 ########## Begin ########## b = re.findall(r'[\d]+',input_str) ########## End ########## print(b)
-
-
Python 正则表达式re模块
-
第1关:正则表达式基础知识
import re text = input() #********** Begin *********# #1.匹配字符单词 Love print(re.findall(r'Love',text)) #2.匹配以 w 开头的完整单词 print(re.findall(r'\bw[A-Za-z]+\b',text)) #3.查找三个字母长的单词(提示:可以使用{m,n}方式) print(re.findall(r'\b[A-Za-z]{3}\b',text)) #********** End **********# -
第2关:re 模块中常用的功能函数(一)
import re text = input() #********** Begin *********# #1.用compile方法,匹配所有含字母i的单词 rr = re.compile(r'\w*i\w*') print(rr.findall(text)) #2.在字符串起始位置匹配字符The是否存在,并返回被正则匹配的字符串 print(re.match('The',text).group()) #3.在整个字符串查看字符is是否存在,并返回被正则匹配的字符串 print(re.search('is',text).group()) #********** End **********# -
第3关:re 模块中常用的功能函数(二)
import re text = input() #********** Begin *********# #1.匹配以t开头的所有单词并显示 itext = re.finditer(r'\bt[A-Za-z]+\b',text) for i in itext: print(i.group()) #2.用空格分割句子 print(re.split(r'\s+',text)) #3.用‘-’代替句子中的空格 print(re.sub(r' ', '-', text)) #4.用‘-’代替句子中的空格,并返回替换次数 print(re.subn(r' ', '-', text)) #********** End **********#
-
-
本作品采用 知识共享署名-相同方式共享 4.0 国际许可协议 进行许可。